Conventional RAM Timing
Refresh is the process of reading a row of memory cells and writing
them back to compensate for the loss of capacitor charge over time.
Row refresh occurs if a target cell is accessed for either read or write.
But must also occur on a regular basis for all cells whether they are
accessed or not.
Scheduled row refreshes slow memory access because they use the same
sense amp as read/write and must complete even of target cell is in
row currently being refreshed.
Memory wait
Economical memory is slower, often requiring multiple CPU clock cycles
to complete a memory cell access.
Reasons :
Address is multiplexed requiring two writes of address to chip.
Read/write only occur after row/column selected.
Memory needs to be refreshed after read.
Refresh may already be occuring on target row, so row and sense amps busy.
These delays are not always predictable and may accumulate.
Most systems use controller chip-set that control memory independent of the
system clock, asynchronously.
The memory controller chip-set is responsible for
Splitting address into row/column to accessing target memory.
Strobing through row refresh as needed.
And Signaling CPU when to 'wait' while doing these.
Wait times can either be hardcoded into the controller or programmed.
Programmed Waits allow user to up/down grade or even overdrive memory.
Wait states provided guide line for the safe wait time for the CPU between
requesting access to memory and the time data storage could be accessed.
Wait states were commonly stored in BIOS based on the model/version of memory
on the system. Some times listed as 4 number 4-2-2-2.
Wait states tend to be larger than needed,
favor fewer botched access over speed.
A CPU issues a memory access request, it then monitors its Ready pin. This
pin tied to the memory controller wait request pin.
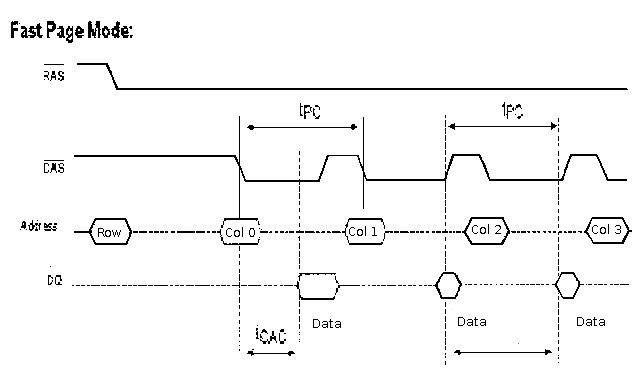
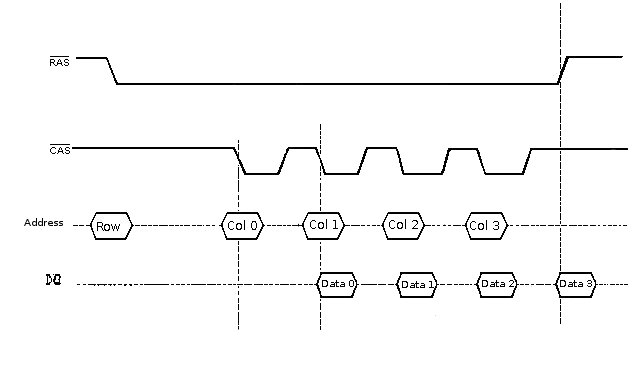
Fast Page RAM
Principle of locality allowed controller to skip repeating of row @
when memory was sequentially accessed - up to 4 sequential addresses.
Fast pages holds row open for up to 4 reads/writes delaying the refresh
delay and avoiding time lost in re-addressing row. Good for burst access.
5 clocks first read, 2 clocks each following 5-2-2-2
EDORAM - extended data out
Pipe-lining - 1st memory cell read while 2nd address being chosen.
5% faster the FPM.
Requires appropriate controller.
5 clocks first read, 1 clocks each following 5-1-1-1
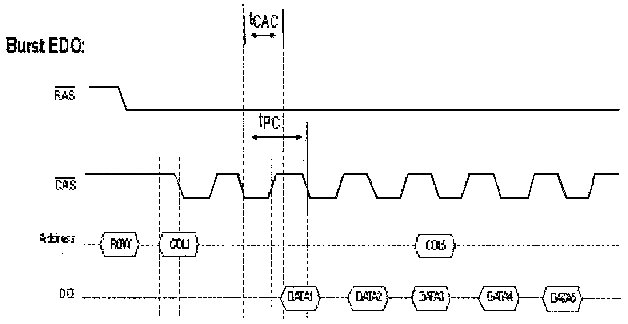
BEDORAM - Burst extended data out
Placed the column sequencing function on the memory chip
50% faster that EDO for large block reads.
Still 5-1-1-1, but worked with faster system clock.
Interleaving to overcome refresh delays.
When row read, it had to be refreshed. By interleaving addresses,
chip had time to refresh row x while x+1 was being read.
SDRAM
{kind=link}
{kind=link}
{kind=link}