Back
Unicode
ASCII - American Standard Code for Information Interchange. (1963,1967,1986)
IBM supported its use, it was not quite ready when they released the 360
architecture.
7-bit - compatible with punch tape and AT&T teletype hardware.
Did away with shift set of alternative characters.
128 value possible.
Represents 0-9, A-Z, a-z, punctuation, and device control.
Some punctuation appears between the sequences 0-9, A-Z, and a-z.
But within each sequence, values are sequential and contiguous
J (74) does follow I (73)
making collation much easier to code.
33 non-printable control characters for controlling output devices.
- teletype and later printers
Print control.
Backspace, linefeed (vt), form feed, tab (ht), carriage return (cr),
linefeed (lf), etc.
# interpreted by device.
Transmission control.
CTS (clear to send), RTS (ready to send), EOT (end of text), etc.
DOS/Windows systems use [cr][lf] (13,10) character pair to mark end
of current line.
Unix/Linux systems use only [lf] (10).
Early Apples and other used only [cr] (13).
Early printers handled [cr] and [lf] separately allowing over-strike
(reprint over same line) or other formatting such as stair-case
indenting.
94 printable A-Z,a-z,0-9 and various punctuation.
1 space - invisible graphic (actual value - not null)
Image of character (glyph) defined by device displaying.
00 - null (nul) ~ neither printable or non-printable, control character(?)
Sometimes refereed to as the null terminator.
In C, marks end of string.
Sometimes represents a NOP as a way to stall while some other action
completes.
High bit usage (in 8 bit byte storage).
For ASCII, set to null
Some systems use as parity check.
A number of system and equipment makers used high bit to define an
additional custom character set.
Some non-English western languages characters. (for French, Spanish, etc.)
Simple graphic symbols - often custom to system or device (Epson vs. IBM)
Smiley faces, lines and angles used to draw boxes on screen.
IBM code page 437
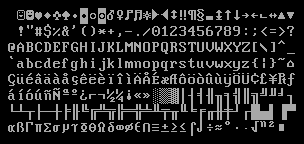 Still geared for English/Western European character sets
Code pages
see wikipedia topic ISO_8859-1
Before Unicode, computer manufacturers used OEM code pages to define
alternative character sets for other languages.
Code pages were firmware re-definitions of the 7-bit ASCII and, possibly,
the hi-bit extension values to reflect the characters of a specific
country.
e.g computers sold to Russia displayed Cyrillic characters.
(and only Cyrillic)
Eventually, these were standardized - ANSI/ISO 8859 code pages
But still based on 1 bytes characters.
* IBM and Microsoft keep separate 'standards'.
See 'code pages' on wikipedia.
Re-introduces the problem of converting information between systems
using different definitions of character sets.
Still geared for English/Western European character sets
Code pages
see wikipedia topic ISO_8859-1
Before Unicode, computer manufacturers used OEM code pages to define
alternative character sets for other languages.
Code pages were firmware re-definitions of the 7-bit ASCII and, possibly,
the hi-bit extension values to reflect the characters of a specific
country.
e.g computers sold to Russia displayed Cyrillic characters.
(and only Cyrillic)
Eventually, these were standardized - ANSI/ISO 8859 code pages
But still based on 1 bytes characters.
* IBM and Microsoft keep separate 'standards'.
See 'code pages' on wikipedia.
Re-introduces the problem of converting information between systems
using different definitions of character sets.